DevOps vs SRE vs Platform Engineering
- Ikpemosi Victoria Braimoh

- Apr 22, 2025
- 8 min read
DevOps, SRE, and platform engineering are three closely related but different disciplines that solve software development problems in three different ways.
When there's a new release, who ensures it gets to the users smoothly? If there's a bug slowing down production deployment, who jumps in to figure out why? When engineers spend more time fixing tools rather than building products, who steps in to make things better?
It may sound like the job of one discipline, but it isn't. These three disciplines each tackle different parts of the puzzle, and despite sharing toolsets and even team members, their goals are different.
Let's examine what each one does, how they differ and complement each other, and why you probably need all three.
What is DevOps?
DevOps emerged to close the gap between developers (who build the software) and operations teams (who run it).
It is a software development approach that combines both development (Dev) and operations (Ops) to improve collaboration and speed. Instead of working separately in silos, developers and IT teams work together to build, test, and deploy software faster and more efficiently.
The primary goal of a DevOps team is to help move code from a developer’s laptop to production smoothly. They do this by automating deployments, setting up CI/CD pipelines and provisioning the infrastructure.
However, DevOps isn't just about the tools or how teams work together. It’s also about the culture, which emphasises shared responsibility, continuous delivery and continuous improvement.
As an organisation, having a good DevOps culture is important because it encourages automation, open communication, and makes software delivery smoother and more reliable.
DevOps metrics
DevOps teams measure effectiveness or success through the DORA metrics, which are:
Deployment frequency: How often can you successfully release to production?
Lead time for changes: How long does it take from code commit to production deployment?
Mean time to recovery (MTTR): How quickly can you recover from failures?
Change failure rate: What percentage of deployments result in failures?
Measuring success with these metrics will definitely help your engineers improve their delivery processes.
What is Site Reliability Engineering (SRE)?

SRE is all about keeping systems reliable, fast, and available. It grew from Google’s engineering culture, combining software engineering with traditional operations.
Software reliability engineers care deeply about uptime, monitoring, incident response, and ensuring users aren’t impacted when things go wrong.
The goal of the SRE department is to focus on building systems that are resilient, scalable, and efficient. They mostly dwell on systems reliability by setting clear availability targets, and proactively preventing failures.
For example, a web app can experience a massive surge in traffic during the holiday season. Yes, everyone is shopping almost at the same time, and it's affecting your application's behaviour.
The SRE team would monitor the performance of each system or server and automatically scale resources to handle the load. If one server fails, the traffic going to that server would be redirected to a healthy server instead. This will enable your users to continue shopping without issues.
To achieve smooth processes, the SRE team has a culture that supports appropriate communication, alignment between teams, and a proactive approach to problem-solving.
SRE metrics
To measure success, SRE teams use key metrics that define system performance and reliability:
Service Level Indicators (SLIs): These are specific measurements, like response time, latency, or even error rates, that show how well a service performs.
Service Level Objectives (SLOs): These set the target performance level based on SLIs. For example, an SLO for availability might be 99.99% uptime.
Service Level Agreements (SLAs): These are formal commitments to customers based on SLOs. They define the expected reliability of the service and outline compensation or corrective actions if those expectations aren’t met.
What is platform engineering?

Platform engineering is a field in software development that focuses on building and maintaining the internal systems, tools, and services that help developers work faster and more efficiently.
Rather than focusing directly on deployments or incidents, platform engineers focus on creating a solid foundation that other teams can build on.
For example, instead of manually setting up infrastructure, configuring deployments, or solving the same problem every time there's a new project, platform engineers provide ready-made or self-service tools and templates that developers can use right away, thereby saving time and effort.
Platform engineering emphasises the following:
Developer Experience: Creating internal developer platforms (IDPs) with excellent developer experience.
Abstraction: This means hiding the complicated parts of infrastructure behind simple tools and interfaces so developers can do things like deploy code or create environments on their own without needing to know all the technical details.
Autonomy: Enabling developer autonomy while maintaining governance. It is very important for developers to have the freedom to build, test, and deploy software independently while ensuring that security, compliance, and best practices are still followed.
This is done by setting up guardrails, automated policies, and approval processes within the platform. With a tool like Kratix, developers can move quickly without waiting for manual approvals, while the platform ensures they stay within the approved guidelines.
Platform engineering metrics
Platform engineering teams often adapt DevOps metrics, such as deployment frequency and lead time for changes, to track the performance and efficiency of their platforms.
However, their focus extends beyond delivery speed to the effectiveness of the developer experience and the reliability of the internal systems they provide.
For example, they might measure:
Platform adoption rate: How many teams or developers actively use the platform.
Time to provision resources: How quickly developers can get what they need via self-service tools.
Error rates in self-service workflows: How often automated processes fail.
Additionally, they ensure security and compliance checks are seamlessly integrated into the development workflow. This could involve tracking compliance adherence rates or policy violation incidents, ensuring the platform balances autonomy with governance.
To achieve these outcomes, platform engineering teams often leverage frameworks that allow developers to embed compliance standards directly into their workflows.
For instance, tools like Kratix enable the creation of reusable templates called Promises that ensure applications align with organisational policies and regulatory requirements automatically.
Tools and technologies powering software engineering
DevOps, SRE, and platform engineering often use the same tools, but how they use those tools and why can be very different.
Kubernetes
Kubernetes is used for container orchestration, network management, storage, scaling, and even self-healing. It abstracts and manages containers through pods, runs them on clusters, and is API-central to declarative infrastructure management.
It automates the deployment and scaling of applications by managing containers across multiple nodes.
DevOps teams use it for software delivery. SREs rely on it to ensure reliability and failover. Platform engineers tend to build on it to create self-service platforms.
Jenkins and GitHub Actions
Jenkins is a popular open-source Continuous Integration and Continuous Deployment (CI/CD) tool that automates software builds, testing, and deployment.
GitHub Actions, on the other hand, is a CI/CD tool built directly into GitHub, making automation seamless for repositories.
They do the same thing and have slight differences. While the DevOps teams rely on them to streamline code integration, SREs use them to automate incident recovery workflows, and platform engineers embed them in self-service developer platforms.
Prometheus and Grafana
Prometheus is a monitoring and alerting tool designed for collecting and analysing metrics from applications and infrastructure, while Grafana, on the other hand, is an open-source visualisation tool used to display metrics collected by Prometheus in interactive dashboards.
These tools can be used to track service performance and get real-time insights.
Terraform
Terraform is an Infrastructure-as-Code (IaC) tool used to automate cloud and on-premises infrastructure provisioning. DevOps teams use it to create and manage cloud environments, SREs make sure the infrastructures are reliable, and even platform engineers use it to define reusable infrastructure templates.
Kratix
Kratix is a framework that stands out, especially in the world of platform engineering. It is an open-source framework for building internal platforms that enable self-service capabilities.
Kratix helps teams deliver internal platforms as a product by making it easier to offer reusable, composable services (like databases, clusters, or pipelines) through a self-service model. It's about giving developers what they need, on demand, without losing control or consistency.
This framework specifically addresses the challenge of building internal developer platforms on Kubernetes. It allows platform teams to define "Promises" (self-service capabilities) that development teams can use through standard Kubernetes APIs.
This approach simplifies the developer experience while improving automation and maintaining governance across teams.
Let's see a simplified example of how a Kratix Promise might look:
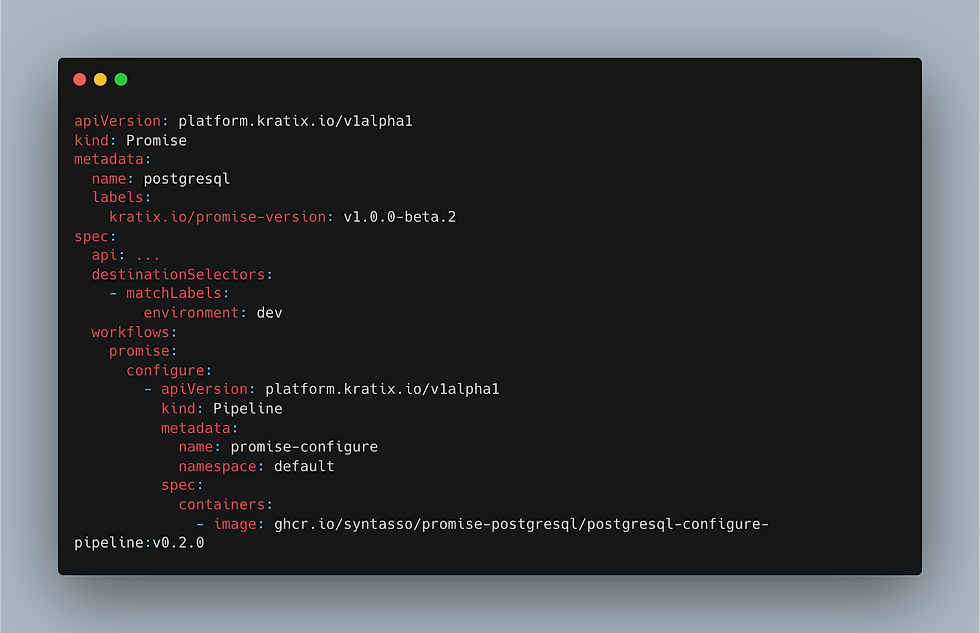
From the above, a software developer can get a database by applying the Promise to their Kubernetes cluster and requesting the associated resource. Kratix will then automate the provisioning process, ensuring each database is configured properly while still maintaining governance and security.
You can see the full Promise on Github: Kratix Postgresql-as-a-Service Promise.
Platform engineering vs DevOps: Similarities & differences
Both platform engineering and DevOps embrace automation and aim to deliver software faster and more reliably.
While they both aim to streamline software delivery, DevOps focuses on collaboration between development and operations, whereas platform engineering builds reusable self-service platforms that developers can use without needing to manage infrastructure themselves.
Here’s how they differ:
Category | Platform engineering | DevOps |
Focus | Providing Internal Developer Platforms (IDPs) for developers | Ensuring a smooth software delivery lifecycle |
Goal | Enable developer autonomy while ensuring governance and compliance | Improve collaboration between development and operations teams. |
Area | Self-service platforms | CI/CD, automation and monitoring tools |
SRE vs DevOps: Similarities & differences
Both SRE and DevOps prioritise automation over manual processes. They both value measuring and improving systems and also encouraging collaboration between the development and operations teams.
However, if DevOps is about speed, SRE is about reliability. Here’s how they differ:
Category | SRE | DevOps |
Focus | Reliability and system performance | Software delivery and operations centred around speeding up deployment. |
Key Metrics | SLIs, SLOs, SLAs | Deployment frequency, lead time for changes, MTTR, change failure rate |
SRE vs. platform engineering: similarities & differences
As seen so far, both SRE and platform engineering aim to improve developer productivity and system reliability. However, here’s how they differ:
Category | SRE | Platform engineering |
Primary focus | System reliability and availability | Developer experience and self-service platforms |
Core responsibility | Maintaining systems | Building IDPs |
Problem approach | Proactive to prevent failures | Proactive in building solutions that prevent common problems |
Customer | End users | Development teams |
How do SRE, DevOps & platform engineering work together?
While distinct, SRE, DevOps and platform engineering complement each other. They work together to make software easier to build, deploy, and continue running smoothly.
While DevOps helps developers and operations teams work better together by automating tasks, SRE focuses on keeping the systems reliable by setting performance targets, monitoring issues, and fixing problems quickly.
Platform engineers, on the other hand, make things easier for developers by creating tools that let them manage infrastructure without needing to worry about all the technical details.
For example, the DevOps team might use CI/CD pipelines to automate the deployments needed to run an application while the SRE team sets up monitoring with Prometheus and alerting to detect failures early.
Meanwhile, the platform engineers could build an internal platform using Kratix, which allows the developers to request infrastructure resources like Kubernetes clusters or databases through a self-service API.
Three distinct disciplines, one goal
Most organisations don't choose between these approaches; they combine them strategically.
With solutions like Kratix, teams can embrace the DevOps culture, integrate SRE practices, and use IDPs to achieve organisational goals, all within a unified framework.
As your organisation grows, you'll likely need all three elements, and this is why Kratix is here to support you on your journey.
Click here to explore how Kratix can help you.



Comments